Labs/Bespin/DesignDocs/TimeMachine
Contents
Time Machine
Time Machine is designed to solve 2 basic problems in Bespin:
- Allow users to get the text back that someone else deleted
- Allow viewing the evolution of some text over time
API
It is currently expected that we will need to create a new API and enhance another.
Historical Revision Information
This new server API allows clients to get at a list of changes to a file over time.
The URL would probably match the /preview/at and /file/at style, so we would use /history/at/project/path
A call to this URL would return a 404 or similar error if the request could not be completed. On success the JSON data structure would look like this:
[
{
source: [vcs|save|undo],
id: "564129cea41d",
date: "Mon Aug 17 2009",
owner: "jwalker",
size: 0.4,
description: "Automated merge with ssh://hg.mozilla.org/labs/bespin/"
},
{ /* further revisions */ }
]
The members are as follows:
- source: 'vcs' indicates that the change comes from the VCS system registered with the project. There can be at most one VCS repo per project. The date, owner and description fields probably come from a call to 'vcs log' or similar.
- id: An arbitary unique ID for use with revisions to the '/file/at' call. Most (all?) VCSs give revision identifiers. Bespin will generate IDs for save|undo sources.
- date: We will need to specify a format for the time.
- owner: VCS specified username for VCS originated change. Bespin specified for other types of change. To begin with, we do not expect to link VCS usernames to bespin usernames. This linkage could be useful over time.
-
size: The size field comes from something like 'diff $file | wc -l' / 'cat $file | wc -l' (clearly that won't work exactly, but the point is the same). From my investigations so far, it would seem that it's going to be a significant performance drain getting this to work.We're not planning on doing a churn graph right now - description: Simple in the VCS case. For the 'save' source we might take the users status on save. For the 'undo' source we might take an editor provided description of the action e.g. 'typing', 'format source'.
Issues
- How do we handle VCS rename/copy operations? Is it valid to include changes made under an old filename and ignore the fact that the file may no longer be valid in its new position. (Answer: we lose the data when you move the file.)
- Can we tie bespin usernames to VCS usernames. Tying them together will helps colorization to be consistent. (Answer: we don't - for now, but should later)
- Can we create descriptions (e.g. 'typing', 'format source') out the back of mobwrite?
- Can we create descriptions for save commands?
- Is what comes out of mobwrite going to be too granular
- How are we going to store all this data?
- Can we create a useful size parameter? Is this going to be viable for SVN and other non-D VCSs? (Answer: We're not attempting this for any VCS for now)
- Is there any benefit in transmitting the diff with the rest of the history? We are currently assuming that there isn't because the files are easily accessible, and only a diff might be slow to make use of if you need to work from the start/end. Also diffs prevent us from interleaving sources.
- For none-D VCSs, what's the performance going to be like? Can we use git svn to mitigate the issues? (Answer: Probably not - for now, we're not supporting the VCS portion on SVN)
It is expected that initially for simplicities sake, we will not be interleaving source, so the diff queue would begin with undo, then save, then vcs info. The system ought to allow source interleaving though.
Access to older revisions
The current plan is to modify the '/file/at' URL to add a 'version' parameter, which specifies the version of the given file.
- /file/at/project/path?version=id
Issues
- Do we need to give access to deleted files. Is there an API for discovering what they are?
- We probably need to easily distinguish the source of a version id without needing to go to vcs / save history and mobwrite in turn.
- What is non-D VCS performance going to be like? (See above)
Data Storage
Currently undo data is stored in a mini repository - repoistory.py. The storage format is defined in the pydoc for that package. Briefly:
The features of this repository are:
- lightweight: ie easy to code in the first instance
- upgradable: so the disk format can evolve to be more efficient
- potentially performant: file reads could be O(n) on history length
It is not however:
- distributed
- non-linear. There is no DAG
The on disk format is a series of lines as follows
hex(time):owner:method:urlencode(comment):data
For example
4aa51a00:joewalker:int:example command:data 4aa61e8f:joewalker:int:another example:more data
Where:
- hex(time): an 8 character string (for the next few years) following the python way of using seconds since the epoch e.g. 4aa61e8f
- owner: is the bespin username of the change creator
- method: is one of [int|ext|delta|zint|zext] Currently the only supported value is 'int' however the following are planned
- int: The contents is stored in the data field (at the end of the line)
- ext: The contents are written to a file whose name is in the data field
- delta: The contents are the value of the previous record with the change in the delta field applied
- zint|zext: As int|ext except the contents are compresses with zlib
- comment: A comment (where possible) for the change
- data: As interpreted by the 'method' field
User Interface
See Dions's blog post for example UI: 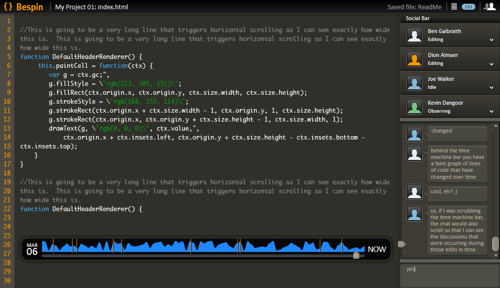
Issues:
- Can we find a way to create the churn information without performance issues?
- Does the change/time scrubber only work when horizontal?
- Can we conserve vertical screen real-estate
- Can we have a fancy fish-eye visualization to save scrolling?
Presenting Diffs
There are several ways to display file differences:
Side By Side
Most IDEs use the side-by-side style to display file comparisons. This has the advantage that it is well tested and understood.

This style has the disadvantage that it is hungry on horizontal screen real estate, where the rest of the IDE is hungry on vertical real estate. This could force us to adopt a more flexible screen layout - It would probably mean that our side-bar display didn't fit well.
It also has the disadvantage that it's hard to find small changes. You can see the line that changed easily, but not how it changed.
Patch Format
Many programmers are familiar with patch format. We could graphically enhance this, for example:

Developers would need to know what the red and green colors stood for. But that's not too much of a learning curve.
This has the disadvantage that it's not editable. I wonder how useful that feature is?
Interlinear
The Enhanced Diff Format is better at showing small changes, but a possibly better option is the interlinear style used in old Bibles.
Where lines are changed rather than being added or removed, rather than taking up 2 lines, the changed text is placed old above new.
I've also used a slightly different style for displaying added and removed lines. Clearly this isn't unique to the interlinear style, and could be applied to the Diff Format.

This option is excellent at showing small changes, and it's possible that this could be made editable, however this would be very tricky.
Font sizes could be tricky. Simply using half height fonts might not be readable. We could use variable line height/baseline shift rather than variable font size.
Word Processors
Word processors have been showing inline differences in an editable form for ages.

This style of display can frequently become messy and confused. This is largely because the word processor developers can't currently use diff to track changes (due to the complexity of tree based diff algorithms - For example remove a word and then type the same word back in again) We should be able to avoid this messiness.